- 当程序运行时,可执行文件首先被加载到内存中,各个
section分别加载到内存中对应的代码段、数据段和BSS段中。 - 需要动态链接的动态库也被加载到内存中,完成代码的链接和重定位操作,以保证程序的正常运行
程序运行的“马甲”:进程
Shell虚拟终端bash本身也是以进程的形式运行
- 当我们在
Shell交互环境下运行./hello时,bash会解析我们的命令和参数,调用fork创建一个子进程,接着调用exec()函数将hello可执行文件的代码段、数据段加载到内存,替换掉子进程的代码段和数据段。 - 然后
bash会解析我们在交互环境下输入的参数,将解析的参数列表argv传递给main,最后跳到main()函数执行。 - 在
Linux系统中,每个进程都使用一个task_struct结构体表示,各个task_struct构成一个链表,由操作系统的调度器管理和维护,每一个进程都会接受操作系统的任务调度,轮流占用CPU去运行 - 程序是安装在磁盘上某个路径下的二进制文件,而进程则是一个程序运行的实例
- 操作系统会从磁盘上加载这个程序到内存,分配相应的资源、初始化相关的环境,然后调度运行。
一个进程实例组成:
- 汇编指令代码、数据
- 包括进程上下文环境、
CPU寄存器状态、打开的文件描述符、信号、分配的物理内存等相关资源
进程内存分类
- 静态内存:在一个进程的地址空间中,代码段、数据段、
BSS段在程序加载运行后,在整个程序运行期间地址不再发生变化 。 - 动态内存:使用
malloc申请的内存、函数调用过程中的栈。
Linux环境下的内存管理
- 在
Linux环境下运行的程序,在编译时链接的起始地址都是相同的,而且是一个虚拟地址。 Linux内核通过页表和MMU硬件来管理内存,完成虚拟地址到物理地址的转换、内存读写权限管理等功能- 每一个应用程序进程都有
4GB大小的虚拟地址空间。为了系统的安全稳定,0~4GB的虚拟地址空间一般分为两部分:用户空间和内核空间。0~3GB地址空间给应用程序使用,而操作系统一般运行在3~4GB内核空间。
应用程序没有权限访问内核空间
- 只能通过中断或系统调用来访问内核空间
- 在
Linux环境下,虽然所有的程序编译时使用相同的链接地址,但在程序运行时,相同的虚拟地址会通过MMU转换,映射到不同的物理内存区域,各个可执行文件被加载到内存不同的物理页上 - 每个进程都有各自的页表,用来记录各自进程中虚拟地址到物理地址的映射关系。
- 通过这种地址管理,每个进程都可以独享一份独立的、私有的
3GB用户空间 - 堆内存一般在
BSS段的后面,随着用户使用malloc申请的内存越来越多,堆空间不断往高地址增长 - 栈空间则紧挨着内核空间,
ARM使用的是满递减堆栈,栈指针会从用户空间的高地址往低地址不断增长 - 堆栈之间的一片茫茫空间中,还有一块区域叫作
MMAP区域,共享库就是使用这片地址空间
物理内存空间布局
对于内存的访问,用户态的进程使用虚拟地址,内核的也基本上使用虚拟地址。
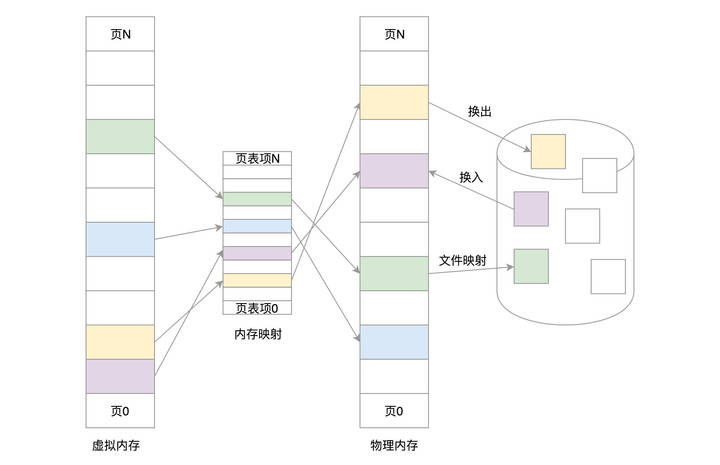
虚拟地址与物理地址的映射
| 页表项 | 用户态 | 内核态 | 备注 |
|---|---|---|---|
| 存储位置 | 每个进程的task_struct中包含一个mm_struct指针,指向该进程的内存管理结构。 | 内核的init_mm是所有进程共享的内存管理结构。 | |
| 地址映射方式 | 用户空间通过四级页表进行虚拟地址到物理地址的转换。 | 内核空间使用直接映射区(Direct Mapping Area, DMA)进行线性映射。 | 内核空间中也有部分使用非线性映射,例如通过vmalloc分配的内存。 |
| 映射创建时机 | 当进程被创建时,其页表和虚拟内存空间被初始化。 | 内核在系统启动时初始化其内存管理结构。 | |
| 映射独立性 | 每个进程拥有独立的页表和虚拟地址空间。 | 内核页表是所有进程共享的。 |
进程独占虚拟内存
| 项目 | 用户地址空间 | 内核地址空间 | 备注 |
|---|---|---|---|
| 地址类型 | 虚拟地址 | 虚拟地址 | 都要经过MMU的翻译,变成物理地址 |
| 生存期 | 随进程创建产生 | 持续存在 | |
| 共享 | 进程独占 | 所有进程共享 | |
| 对应物理空间 | 分散且不固定 | 提前固定下来一片连续的物理地址空间,所有进程共享 |
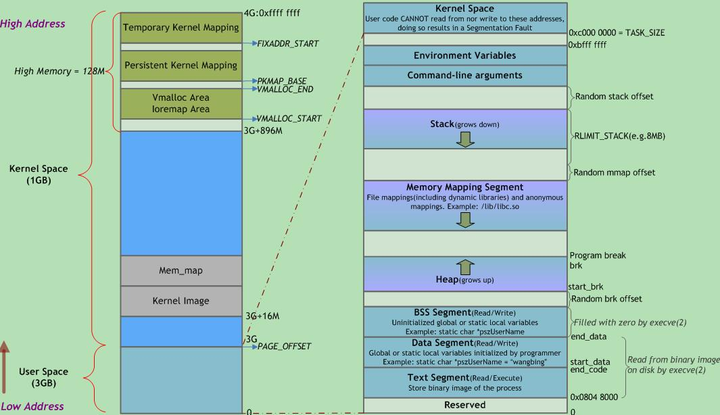
在代码中的体现
内核使用内存描述符mm_struct来表示进程的地址空间,该描述符表示着进程所有地址空间的信息

struct task_struct{
...
struct mm_struct *mm;
struct mm_struct *active_mm;
...
void *stack;//指向内核栈的指针
};在内核里面,无论是从哪个进程进来的,看到的都是同一个内核空间,看到的都是同一个进程列表。虽然内核栈是各用个的,但是如果想知道的话,还是能够知道每个进程的内核栈在哪里的。所以,如果要访问一些公共的数据结构,需要进行锁保护。
内存管理的进程和硬件背景
页表的位置
每个进程都有独立的地址空间,为了这个进程独立完成映射,每个进程都有独立的进程页表,这个页表的最顶级的 pgd 存放在 task_struct 中的 mm_struct 的 pgd 变量里面。
在一个进程新创建的时候,会调用 fork,对于内存的部分会调用 copy_mm,里面调用 dup_mm。
- 创建新的mm_struct
- 复制父进程相应内容
- 调用mm_init初始化
// Allocate a new mm structure and copy contents from the mm structure of the passed in task structure.
static struct mm_struct *dup_mm(struct task_struct *tsk){
struct mm_struct *mm, *oldmm = current->mm;
mm = allocate_mm();
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm, tsk, mm->user_ns))
goto fail_nomem;
err = dup_mmap(mm, oldmm);
return mm;
}mm_init调用mm_alloc_pgd,分配全局页目录项,赋值给mm_struct的pdg成员变量。
static inline int mm_alloc_pgd(struct mm_struct *mm){
mm->pgd = pgd_alloc(mm);
return 0;
}一个进程的虚拟地址空间包含用户态和内核态两部分。
为了从虚拟地址空间映射到物理页面,页表也分为用户地址空间的页表和内核页表。在内核里面,映射靠内核页表,这里内核页表会拷贝一份到进程的页表。
如果是用户态进程页表,会有 mm_struct 指向进程顶级目录 pgd,对于内核来讲,也定义了一个 mm_struct,指向 swapper_pg_dir(指向内核最顶级的目录 pgd)。
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
// pgd 页表最顶级目录
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
INIT_MM_CONTEXT(init_mm)
};页表的应用
一个进程 fork 完毕之后,有了内核页表(内核初始化时即弄好了内核页表, 所有进程共享),有了自己顶级的 pgd,但是对于用户地址空间来讲,还完全没有映射过(用户空间页表一开始是不完整的,只有最顶级目录pgd这个“光杆司令”)。这需要等到这个进程在某个 CPU 上运行,并且对内存访问的那一刻了
当这个进程被调度到某个 CPU 上运行的时候,要调用 context_switch 进行上下文切换。对于内存方面的切换会调用 switch_mm_irqs_off,这里面会调用 load_new_mm_cr3。
cr3 是 CPU 的一个寄存器,它会指向当前进程的顶级 pgd。如果 CPU 的指令要访问进程的虚拟内存,它就会自动从cr3 里面得到 pgd 在物理内存的地址,然后根据里面的页表解析虚拟内存的地址为物理内存,从而访问真正的物理内存上的数据。
这里需要注意两点。第一点,cr3 里面存放当前进程的顶级 pgd,这个是硬件的要求。cr3 里面需要存放 pgd 在物理内存的地址,不能是虚拟地址。第二点,用户进程在运行的过程中,访问虚拟内存中的数据,会被 cr3 里面指向的页表转换为物理地址后,才在物理内存中访问数据,这个过程都是在用户态运行的,地址转换的过程无需进入内核态。
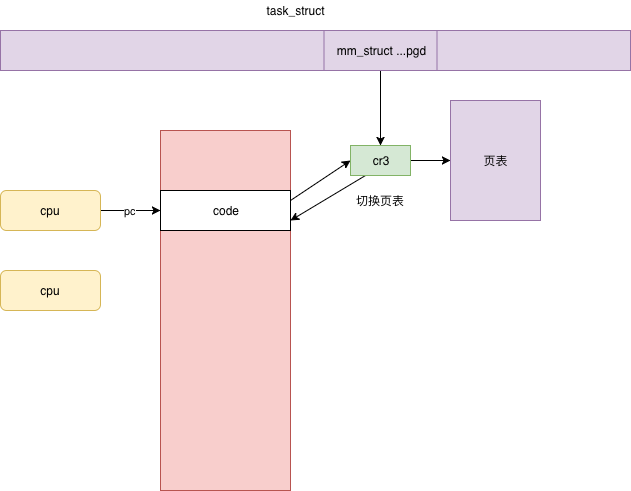
通过缺页中断填充页表
当程序访问的页不在物理内存中时发生的中断。
操作系统捕获中断,检查原因,如果合法但不在内存中,则从磁盘加载所需页面,并更新页表。
内存管理并不直接分配物理内存,只有等你真正用的那一刻才会开始分配。只有访问虚拟内存的时候,发现没有映射多物理内存,页表也没有创建过,才触发缺页异常。进入内核调用 do_page_fault,一直调用到 __handle_mm_fault,__handle_mm_fault 调用 pud_alloc 和 pmd_alloc,来创建相应的页目录项,最后调用 handle_pte_fault 来创建页表项。
static noinline void
__do_page_fault(struct pt_regs *regs, unsigned long error_code,
unsigned long address){
struct vm_area_struct *vma;
struct task_struct *tsk;
struct mm_struct *mm;
tsk = current;
mm = tsk->mm;
// 判断缺页是否发生在内核
if (unlikely(fault_in_kernel_space(address))) {
if (vmalloc_fault(address) >= 0)
return;
}
......
// 找到待访问地址所在的区域 vm_area_struct
vma = find_vma(mm, address);
......
fault = handle_mm_fault(vma, address, flags);
......
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags){
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
int ret;
pgd = pgd_offset(mm, address);
p4d = p4d_alloc(mm, pgd, address);
......
vmf.pud = pud_alloc(mm, p4d, address);
......
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
......
return handle_pte_fault(&vmf);
}以handle_pte_fault 的一种场景 do_anonymous_page为例:先通过 pte_alloc 分配一个页表项,然后通过 alloc_zeroed_user_highpage_movable 分配一个页,接下来要调用 mk_pte,将页表项指向新分配的物理页,set_pte_at 会将页表项塞到页表里面。
static int do_anonymous_page(struct vm_fault *vmf){
struct vm_area_struct *vma = vmf->vma;
struct mem_cgroup *memcg;
struct page *page;
int ret = 0;
pte_t entry;
......
if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
return VM_FAULT_OOM;
......
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
......
entry = mk_pte(page, vma->vm_page_prot);
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
......
}
下缺页异常(缺页中断)与普通中断的区别
- 缺页中断在指令执行期间产生和处理中断信号,而一般中断在一条指令执行完成后检查和处理中断信号。
- 缺页中断返回到该指令的开始重新执行该指令,而一般中断返回回到该指令的下一个指令执行。
颠簸
工作集的大小超过RAM大小,操作系统不断在虚拟内存中交换
栈的管理
大多数的处理器架构,都有实现硬件栈。有专门的栈指针寄存器,以及特定的硬件指令来完成 入栈/出栈 的操作。
栈是
C语言运行的基础,同时也是操作系统多线程管理的基石。
C语言函数中的局部变量、传递的实参、返回的结果、编译器生成的临时变量都是保存在栈中的,离开了栈,C语言就无法运行。- 在很多嵌入式系统的启动代码中,你会看到:系统一上电开始运行的都是汇编代码,在跳到第一个
C语言函数运行之前,都要先初始化栈空间。 - 操作系统最基本的功能是支持多线程编程,支持中断和异常处理,每个线程都有专属的栈,中断和异常处理也具有专属的栈。
入栈顺序
采用自右向左的入栈顺序,主要原因是为了支持可变长参数形式
- 例如
printf(const char *format,...),编译器通过format的%占位符的个数来获取参数的个数 - 未知个数的参数先入栈,
format再入栈,最后压pc入栈这时候要想知道参数的个数只需要将栈顶指针加2即可读取到format。
用户栈与内核栈的切换
内核在创建进程的时候,在创建task_struct的同时,会为进程创建相应的堆栈。每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。
- 用户栈:进程在用户空间运行时,cpu堆栈指针寄存器里面的内容是用户堆栈地址。
- 内核栈:进程在内核空间时,cpu堆栈指针寄存器里面的内容是内核栈空间地址。
- 陷入内核时:将用户态堆栈地址保存在内核栈中,设置
SP Register的内容为内核栈的地址。 - 恢复用户态:将用户栈的地址赋值给
SP Register。
关键在于如何获得内核栈地址:
- 一旦进程从内核态返回到用户态后,内核栈中保存的信息无效,因此,每次陷入内核时得到的内核栈总是空的,直接报内核栈的栈顶地址赋值给
SP Register。
为什么需要单独的进程内核栈
因为同时可能有多个进程在内核运行。
进程内核栈在进程创建的时候,通过 slab 分配器从 thread_info_cache 缓存池中分配出来,其大小为 THREAD_SIZE,一般来说是一个页大小 4K;
进程切换→内核栈切换→用户栈切换
- 内核栈:在
__switch_to里面切换,也就是将current_task指向当前的task_struct。里面的void *stack指针,指向的就是当前的内核栈。 - 内核栈的栈顶指针:在
__switch_to_asm里面已经切换了栈顶指针,并且将栈顶指针在__switch_to加载到TSS里。 - 用户栈的栈顶指针:在内核栈顶部的
pt_regs结构里面。当从内核返回用户态运行的时候,pt_regs里面有所有当时在用户态的时候运行的上下文信息
主线程的用户栈与一般线程的线程栈
| 用户栈 | 进程主线程 | 一般线程 |
|---|---|---|
| 栈地址 | 进程用户栈 | 在进程的堆里创建 |
| 指令指针初始位置 | main函数 | 为线程指定的函数 |
中断栈
硬件中断的实现通过一个导线和 CPU 相连来传输中断信号,软件上会有特定的指令,例如执行系统调用创建线程的指令,而 CPU 每执行完一个指令,就会检查中断寄存器中是否有中断,如果有就取出然后执行该中断对应的处理程序。
当系统收到中断事件后,进行中断处理的时候,也需要中断栈来支持函数调用。由于系统中断的时候,系统当然是处于内核态的,所以中断栈是可以和内核栈共享的。但是具体是否共享,这和具体处理架构密切相关。ARM 架构就没有独立的中断栈。
默认栈空间
- 默认栈空间大小通常为8MB,范围可能在2MB到10MB之间
- 可使用
ulimit -s <stack_size>调整栈空间大小 <stack_size>以KB为单位- 修改仅在当前
shell会话中有效 - 持久化修改需将命令添加到用户
shell配置文件
栈的初始化
栈的初始化其实就是栈指针
SP的初始化
- 在系统启动过程中,内存初始化后,将栈指针指向内存中的一段空间,就完成了栈的初始化
- 栈指针指向的这片内存空间被称为栈空间。
ARM处理器则使用R13寄存器(SP)和R11寄存器(FP)来管理堆栈。ARM处理器使用的是满递减栈,在Linux环境下,栈的起始地址一般就是进程用户空间的最高地址,紧挨着内核空间,栈指针从高地址往低地址增长。
在
Linux环境下,我们可以通过下面的命令来查看和设置栈的大小。
# ulimit -s // 查看栈大小,单位是 KB
8192
# ulimit -s 4096 // 设置栈空间大小为 4MB
Linux默认给每一个用户进程栈分配8MB大小的空间
防止栈溢出,可以参考下面的一些原则
- 尽量不要在函数内使用大数组,如果确实需要大块内存,则可以使用
malloc申请动态内存。 - 函数的嵌套层数不宜过深。
- 递归的层数不宜太深。
函数调用
每个函数的栈空间都被称为栈帧(
Frame Pointer,FP)
- 每一个栈帧都使用两个寄存器
FP和SP来维护,FP指向栈帧的底部,SP指向栈帧的顶部 - 函数的栈帧除了保存局部变量和实参,还用来保存函数的上下文。
- 我们在
main()函数中调用了f()函数,main()函数的栈帧基址FP、main()函数的返回地址LR,都需要保存在f()函数的栈帧中。 SP总是指向当前正在运行函数栈帧的栈顶FP总是指向当前运行函数的栈底。
每一个函数栈帧中
- 要保存局部变量、函数实参、函数调用者的返回地址
- 有时候编译过程中的一些临时变量也会保存到函数的栈帧中
- 多个栈帧通过
FP构成一个链,这个链就是某个进程的函数调用栈 - 每个函数栈帧中都保存着上一级函数的返回地址
LR和它的栈帧空间起始地址FP,当函数运行结束时,可根据这些信息返回上一级函数继续运行 - 前
4个参数使用寄存器传递,剩余的参数则压入堆栈保存 C语言默认使用cdecl调用惯例。参数传递时按照从右到左的顺序依次压入堆栈,栈的清理方则由函数调用者caller管理。- 使用
cdecl调用惯例的好处是可以预先知道参数和返回值大小,而且可以支持变参函数的调用,如printf()函数。 FP寄存器不仅可以向前偏移访问本函数栈帧的内存单元,还可以向后偏移,到上一级函数的栈帧中获取要传递的实参。
形参与实参
形参只有在函数被调用时才会在函数栈帧内分配存储单元,用来接收传进来的实参值。函数运行结束后,形参单元随着栈帧的销毁而被释放
栈与作用域
- 函数只有在被调用的时候才会在内存中开辟一个栈帧空间,在这个栈空间里存储局部变量及传进来的函数实参等。
全局变量的作用域
- 全局变量的作用域由文件来限定。
- 可使用
extern进行扩展,被其他文件引用。 - 可以使用
static进行限制,只能在本文件中被引用
局部变量的作用域
- 局部变量的作用域由
{}限定 - 可以使用
static修饰局部变量来改变它们的存储属性(生命周期),但不能改变其作用域。
栈溢出攻击原理
GCC编译器为了防止数组越界访问
- 一般会在用户定义的数组末尾放入一个保护变量,并根据此变量是否被修改来判断数组是否越界访问。
- 若发现这个变量值被覆盖,就会给当前进程发送一个
SIGABRT信号,终止当前进程的运行
堆内存管理
堆是Linux进程空间中一片可动态扩展或缩减的内存区域,一般位于BSS段的后面。
内存申请相关的其他函数
#include <stdlib.h> /* 包含标准库头文件 */
/*
* 分配指定大小的内存块
* @size: 要分配的内存块的大小,以字节为单位
* 返回: 成功时返回指向分配的内存块的指针,失败时返回 NULL
*/
void *malloc(size_t size);
/*
* 释放之前分配的内存块
* @ptr: 指向要释放的内存块的指针
* 注意: 如果 ptr 为 NULL,则不执行任何操作
*/
void free(void *ptr);
/*
* 分配足够容纳 nmemb 个元素的内存块,每个元素大小为 size 字节,并初始化为零
* @nmemb: 元素的数量
* @size: 每个元素的大小,以字节为单位
* 返回: 成功时返回指向分配并初始化的内存块的指针,失败时返回 NULL
*/
void *calloc(size_t nmemb, size_t size);
/*
* 调整之前分配的内存块的大小
* @ptr: 指向之前分配的内存块的指针
* @size: 新的内存块大小,以字节为单位
* 返回: 成功时返回指向调整后的内存块的指针,失败时返回 NULL
* 注意: 如果 ptr 为 NULL,则等效于 malloc(size)
* 如果 size 为零,并且 ptr 不为 NULL,则等效于 free(ptr)
*/
void *realloc(void *ptr, size_t size);堆内存与栈的区别
| 特性 | 栈 (Stack) | 堆 (Heap) |
|---|---|---|
| 空间分配 | 由操作系统自动分配和释放 | 由程序员手动分配和释放 |
| 缓存方式 | 使用一级缓存 | 存储在二级缓存或主存中 |
| 生长方向 | 向下增长(向地址较小的方向分配) | 向上增长(向地址较大的方向分配) |
| 生命周期 | 随着函数调用自动分配和释放 | 分配时不自动释放,需手动释放 |
| 空间大小 | 一般较小,最多约2MB | 较大,接近3GB(32位程序) |
| 内存碎片 | 不会产生内存碎片 | 可能由于动态分配和释放导致内存碎片问题 |
Linux堆内存管理
malloc()/free()函数的底层实现,其实就是通过系统调用brk向内核的内存管理系统申请内存。
- 当用户要申请的内存比较大时,如大于
128KB,一般会通过mmap系统调用直接映射一片内存,使用结束后再通过ummap系统调用归还这块内存 mmap区域则紧挨着stack,mmap区域包括进程动态链接时加载到内存的动态链接器ld-2.23.so、动态共享库、使用mmap申请的动态内存。heap区和mmap区的起始地址和stack一样,也不是固定不变的。为了防止黑客攻击,每次程序运行时,它们都会以一个随机偏移作为起始地址。mm_struct结构体中的start_brk成员表示堆区的起始地址- 用户使用
malloc()申请的内存大小大于当前的堆区时,malloc()就会通过brk()系统调用,修改mm_struct中的成员变量brk来扩展堆区的大小 brk()系统调用的核心操作其实就是通过扩展数据段的边界来改变数据段的大小的。- 大量的系统调用会让处理器和操作系统在不同的工作模式之间来回切换:操作系统要在用户态和内核态之间来回切换,
CPU要在普通模式和特权模式之间来回切换,每一次切换都意味着各种上下文环境的保存和恢复,频繁地系统调用会降低系统的性能
allocator
glibc中实现的内存分配器(allocator)可以直接对堆内存进行维护和管理。
- 当用户使用
free()释放内存时,释放的内存并不会立即返回给内核,而是被内存分配器接收,缓存在用户空间 - 内存分配器将这些内存块通过链表收集起来,等下次有用户再去申请内存时,可以直接从链表上查找合适大小的内存块给用户使用,如果缓存的内存不够用再通过
brk()系统调用去内核“批发”内存 - 内存分配器相当于一个内存池缓存,通过这种操作方式,大大减少了系统调用的次数,从而提升了程序申请内存的效率,提高了系统的整体性能。
Linux环境下的C标准库glibc使用ptmalloc/ptmalloc2作为默认的内存分配器,- 对于每一个用户申请的内存块,
ptmalloc都使用一个malloc_chunk结构体来表示,每一个内存块被称为chunk
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free) */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead */
struct malloc_chunk* fd; /* double links -- used only if free */
struct malloc_chunk* bk; /* for large blocks: pointer to next larger size */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};- 用户程序调用
free()释放掉的内存块并不会立即归还给操作系统,而是被用户空间的ptmalloc接收并添加到一个空闲链表中 malloc_chunk结构体中的fd和bk指针成员将每个内存块链成一个双链表,不同大小的内存块链接在不同的链表上,每个链表都被我们称作bin,ptmalloc内存分配器共有128个bin,使用一个数组来保存这些bin的起始地址。- 每一个
bin都是由不同大小的内存块链接而成的链表,根据内存块大小的不同,我们可以对这些bins进行分类。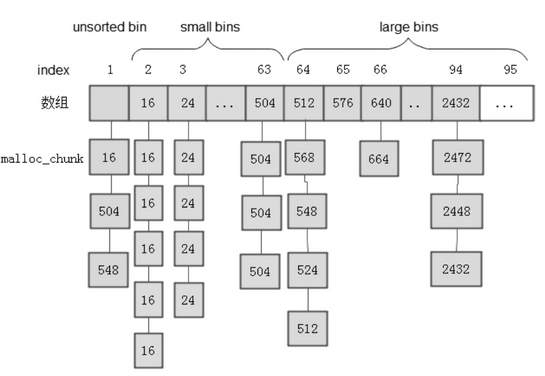
- 用户释放掉的内存块不会立即放到
bins中,而是先放到unsorted bin中 - 等用户下次申请内存时,会首先到
unsorted bin中查看有没有合适的内存块,若没有找到,则再到small bins或large bins中查找。small bins中一共包括62个bin,相邻两个bin上的内存块大小相差8字节,内存数据块的大小范围为[16,504],大于504字节的大内存块要放到large bins对应的链表中 - 除了数组中的这些
bins,还有一些特殊的bins,如fast bins。用户释放掉的小于M_MXFAST(32位系统下默认是64字节)的内存块会首先被放到fast bins中 fast bins由单链表构成,FILO栈式操作,运行效率高,相当于small bins的缓存。
堆内存的分配流程
- 空闲内存链表
- 当用户申请一块内存时,内存分配器就根据申请的内存大小从
bins查找合适的内存块 - 当申请的内存块小于
M_MXFAST时,ptmalloc分配器会首先到fast bins中去看看有没有合适的内存块,如果没有找到,则再到small bins中查找。如果要申请的内存块大于512字节,则直接跳过small bins,直接到unsorted bin中查找。 - 在适当的时机,
fast bins会将物理相邻的空闲内存块合并,存放到unsorted bin中 - 内存分配器如果在
unsorted bin中没有找到合适大小的内存块,则会将unsorted bins中物理相邻的内存块合并,根据合并后的内存块大小再迁移到small bins或large bins中 ptmalloc接着会到large bins中寻找合适大小的内存块。假设没有找到大小正好合适的内存块,一些大的内存块将会被分割成两部分:一部分返回给用户使用,剩余部分则放到unsorted bin中。- 如果在
large bins中还没有找到合适的内存块,这时候就要到top chunk上去分配内存
top chunk
top chunk是堆内存区顶部的一个独立chunk,它比较特殊,不属于任何bins- 若用户申请的内存小于
top chunk,则top chunk会被分割成两部分:一部分返回给用户使用,剩余部分则作为新的top chunk
sbrk/mmap
- 若用户申请的内存大于
top chunk,则内存分配器会通过系统调用sbrk()/mmap()扩展top chunk的大小 - 用户第一次调用
malloc()申请内存时,ptmalloc会申请一块比较大的内存,切割一部分给用户使用,剩下部分作为top chunk。
mmap
- 当用户申请的内存大于
M_MMAP_THRESHOLD(默认128KB)时,内存分配器会通过系统调用mmap()申请内存 - 使用
mmap映射的内存区域是一种特殊的chunk,这种chunk叫作mmap chunk。当用户通过free()函数释放掉这块内存时,内存分配器再通过munmap()系统调用将其归还给操作系统,而不是将其放到bin中。
堆内存测试程序
当堆内存中相邻的两个内存块都被释放且处于空闲状态时,ptmalloc在合适的时机,会将这两块内存合并成一块大内存,并在bins上更新它们的维护信息
当函数一级一级地调用又退出
- 栈中的函数栈帧是如何创建和销毁的
- FP和SP指针是如何移动的
当函数内使用malloc()/free() 申请释放内存时
- 堆区的内存是如何变化的
- brk指针是如何移动的
- glibc中的内存分配器ptmalloc又是如何工作的
mmap映射
当用户使用malloc申请大于128KB的堆内存时,内存分配器会通过mmap系统调用,在Linux进程虚拟空间中直接映射一片内存给用户使用
-
无论是动态链接器、动态共享库的加载,还是大于
128KB的堆内存申请,都和这个区域息息相关 -
既然已经有堆区和栈区了,为什么还要使用这片映射区域?
-
这片映射区域的内存有什么特点?
-
怎么使用它?
-
操作系统是如何管理和维护的?
-
当我们运行一个程序时,需要从磁盘上将该可执行文件加载到内存
将文件加载到内存有两种常用的操作方法
- 一种是通过常规的文件
I/O操作,如read/write等系统调用接口 - 一种是使用
mmap系统调用将文件映射到进程的虚拟空间,然后直接对这片映射区域读写即可。
磁盘缓冲机制
为了提高读写效率,减少I/O读盘次数以保护磁盘,Linux内核基于程序的局部原理提供了一种磁盘缓冲机制
当应用程序读磁盘文件时
- 会先到缓存中看数据是否存在,若数据存在就直接读取并复制到用户空间
- 若不存在,则先将磁盘数据读取到页缓存(
page cache)中,然后从页缓存中复制数据到用户空间的buf中
当应用程序写数据到磁盘文件时
- 会先将用户空间
buf中的数据写入page cache - 当
page cache中缓存的数据达到设定的阈值或者刷新时间超时,Linux内核会将这些数据回写到磁盘中
为了减少系统调用的次数,
glibc决定进一步优化
- 在用户空间开辟一个
I/O缓冲区,并将系统调用read()/write()进一步封装成fread()/fwrite()库函数 - 用户可以通过这个
FILE类型的文件指针,调用fread()/fwrite()C标准库函数来读写文件 - 当应用程序通过
fread()函数读磁盘文件时,数据从内核的页缓存复制到I/O缓冲区,然后复制到用户的buf2中 - 当
fread第二次读写磁盘文件时会先到I/O缓冲区里查看是否有要读写的数据,如果有就直接读取,如果没有就重复上面的流程,重新缓存
I/O缓冲区通过减少系统调用的次数来降低系统调用的开销,但也增加了数据在不同缓冲区复制的次数:一次读写流程要完成两次数据的复制操作。当程序要读写的数据很大时,这种文件I/O的开销也是很大的,得不偿失
- 我们可以通过
mmap系统调用将文件直接映射到进程的虚拟地址空间中,地址与文件数据一一对应,对这片内存映射区域进行读写操作相当于对磁盘上的文件进行读写操作 - 这种映射方式减少了内存复制和系统调用的次数,可以进一步提高系统性能。
将文件映射到内存
mmap()的函数原型如下。
/*
* Memory map a file or device into memory.
* @addr: Desired start address of the mapping.
* If this is NULL, the kernel will choose the address.
* @length: The length of the mapping, in bytes.
* @prot: The protection for the mapping:
* - PROT_EXEC: The mapping is executable.
* - PROT_READ: The mapping is readable.
* - PROT_WRITE: The mapping is writable.
* - PROT_NONE: The mapping is not accessible.
* @flags: Control the mapping:
* - MAP_SHARED: Changes are shared.
* - MAP_PRIVATE: Changes are private.
* - MAP_ANONYMOUS: Anonymous mapping.
* @fd: The file descriptor of the file to map.
* If this is -1, the mapping is anonymous.
* @offset: The offset into the file where the mapping starts.
*/
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);mmap映射实现机制分析
task_struct结构体的mm_struct成员用来描述当前进程的内存布局信息- 一个进程的虚拟地址空间分为不同的区域,如代码段、数据段、
mmap区域等,每一个区域都使用vm_area_struct结构体对象来描述。
/*
* This is the main data structure for memory management in the kernel.
* It represents a single virtual memory area in a process's address space.
*/
struct vm_area_struct {
unsigned long vm_start; /* Start address of the VM area within the mm */
unsigned long vm_end; /* End address of the VM area within the mm */
struct vm_area_struct *vm_next, *vm_prev; /* Linked list of VMAs */
struct file *vm_file; /* File mapped to this VM area, if any */
void *vm_private_data; /* Private data, was vm_pte for shared memory */
};- 当用户程序开始读写进程虚拟空间中的这片映射区域时,发现这片映射区域还没有分配物理内存,就会产生一个请页异常,
Linux内存管理子系统就会给该片映射内存分配物理内存,将要读写的文件内容读取到这片内存,最后将虚拟地址和物理地址之间的映射关系写入该进程的页表 - 一块普通的内存,显卡、
Frambuffer都是一个文件,都可以映射到内存,既减少了系统调用的次数,又减少了数据复制的次数,性能相比文件I/O显著提高
把设备映射到内存
- 在嵌入式
ARM平台上,LCD控制器通常以IP的形式集成到SoC芯片,也要占用一部分内存空间作为显示内存 Linux内核在驱动层对不同的LCD硬件设备进行抽象,屏蔽底层的各种硬件差异和操作细节,抽象出一个帧缓存设备——Framebuffer。Framebuffer是Linux对显存抽象的一种虚拟设备,对应的设备文件为/dev/fb,它为Linux的显示提供了统一的接口
多进程共享动态库
- 一个被加载到内存的动态库是如何被多个进程共享的
- 动态库
libtest.so只加载到物理内存一次,后面的进程如果需要链接这个动态库,直接将该库文件映射到自身进程的虚拟空间即可。 - 同一个动态库虽然被映射到了多个进程的不同虚拟地址空间,但是通过MMU地址转换,都指向了物理内存中的同一块区域。
内存泄漏
申请了一块内存空间,使用完毕后没有释放掉
预防内存泄漏
- 内存申请后及时地释放,两者要配对使用,内存释放后要及时将指针设置为
NULL,使用内存指针前要进行非空判断 - 编程时指明需要释放由谁释放内存。
- 将分配的内存的指针以链表的形式自行管理,使用完毕之后从链表中删除,程序结束时可检查改链表。
smart poninter。
内存泄漏检测:MTrace
MTrace是Linux系统自带的一个工具,它通过跟踪内存的使用记录来动态定位用户代码中内存泄漏的位置- 广义上的内存泄漏指系统频繁地进行内存申请和释放,导致内存碎片越来越多,无法再申请一片连续的大块内存。
内存碎片 ⭐⭐
定义
内存碎片是指在内存管理过程中产生的未被有效利用的零散、不连续的内存空间。
- 内部碎片:是由于固定大小的内存分配方式或对齐要求等原因导致的未被利用的小空间。当分配给进程的内存块大于所需的大小时,其中的剩余空间就成为了内部碎片。
- 外部碎片:是由于存在未分配的连续内存空间太小而不能满足分配请求,从而导致这些内存无法被有效利用。
解决方式
- 段页式管理:采用虚拟内存管理技术,将物理内存划分为不同的页或段,以更灵活地管理和分配内存空间,减少碎片化。
- 使用内存池:通过分配一定数量的内存块,由内存池来管理分配和回收,减少频繁的内存分配和释放,从而减少碎片化。
内存池⭐
内存池
Memory Pool是一种动态内存分配与管理技术。
- 通常情况下习惯使用
new/delete/malloc/free等API申请分配和释放内存 - 当程序长时间运行时,由于所申请的内存块大小不定,频繁使用时会造成大量的内存碎片从而降低程序和操作系统的性能。
- 内存池则是在真正使用内存之前,先申请分配一大块内存(内存池)留作备用,当我们申请内存时,从池中取出一块动态分配的内存,释放内存时,再将我们使用的内存释放到我们申请的内存池内,再次申请内存池也可以再取出来使用。并且,尽量与周边的内存块合并。
- 若内存池不够时,则自动扩大内存池,从操作系统中申请更大的内存池
常见的内存错误及检测
常见的内存错误一般主要分为以下几种类型:
- 内存越界、内存踩踏、多次释放、非法指针。
- 发生段错误的根本原因在于非法访问内存,即访问了权限未许可的内存空间。
使用core dump调试段错误
在Linux环境下运行的应用程序,由于各种异常或Bug,会导致程序退出或被终止运行。此时系统会将该程序运行时的内存、寄存器状态、堆栈指针、内存管理信息、各种函数的堆栈调用信息保存到一个core文件中。
在嵌入式系统中,这些信息有时也会通过串口打印出来。
内存踩踏
- 数组越界
- 使用未初始化或已释放的指针
- 栈溢出
内存踩踏监测:mprotect
mprotect()是Linux环境下一个用来保护内存非法写入的函数,它会监测要保护的内存的使用情况,一旦遇到非法访问就立即终止当前进程的运行,并产生一个core dump。
- 页(
page)是Linux内存管理的基本单元,在32位系统中,一个页通常是4096字节,mprotect()要保护的内存单元通常要以页地址对齐,我们可以使用memalign()函数申请一个以页地址对齐的一片内存。
#include <sys/mman.h> /* Memory management */
/*
* Change the protection of a memory region.
* @addr: The starting address of the memory region.
* @len: The length of the memory region.
* @prot: The new protection flags for the memory region.
* Can be PROT_EXEC, PROT_READ, PROT_WRITE, or PROT_NONE.
* Returns: 0 on success, -1 on failure with errno set.
*/
int mprotect(void *addr, size_t len, int prot);内存检测神器:Valgrind
Valgrind包含一套工具集,其中一个内存检测工具Memcheck可以对我们的内存进行内存覆盖、内存泄漏、内存越界检测。 #todo